A director I worked with faced a hard call: ship with a known bug, or slip the release date again. He opened ChatGPT, typed out the tradeoff, read the answer aloud to the room, and moved on. Nobody argued. Nobody pushed back. The AI had spoken, and he treated its output as a verdict instead of an input.
I watched the room go quiet in a way I recognized. Not agreement. Abdication.

The Gap Nobody Talks About
Here's the thing about AI and confidence: they don't move together, and most leaders assume they do.
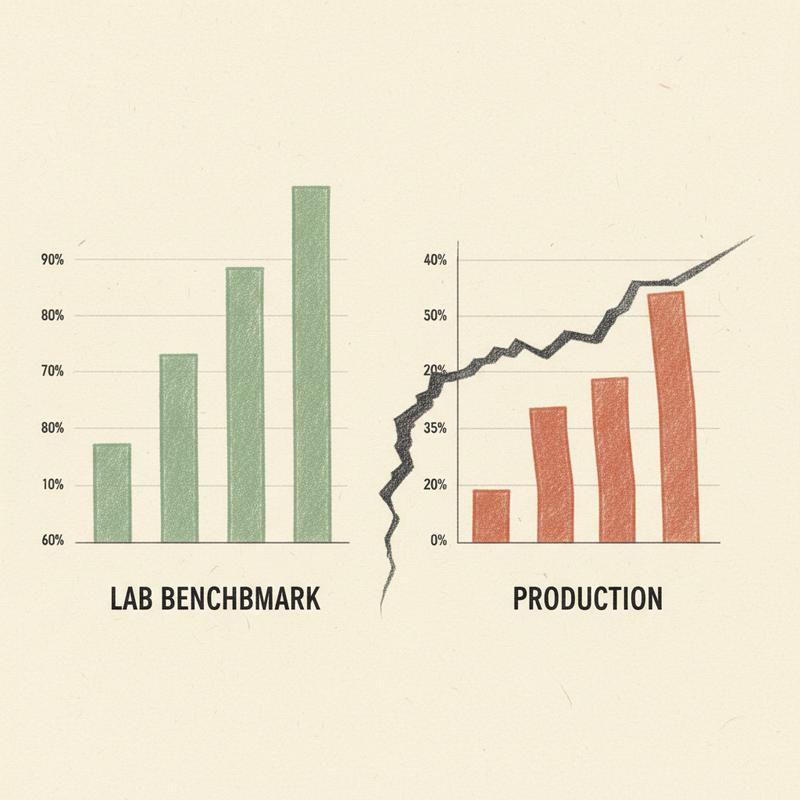
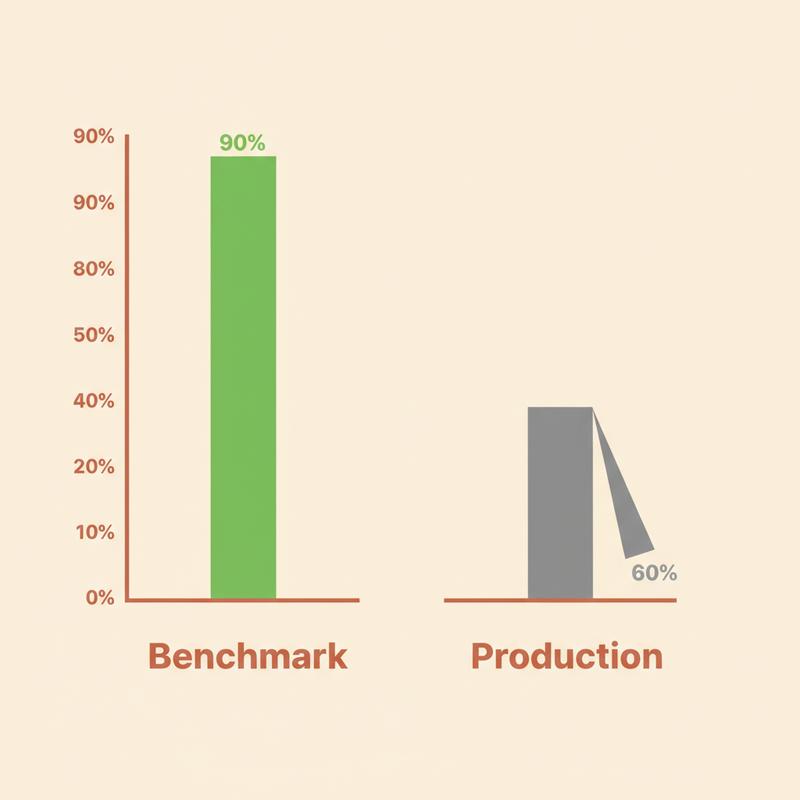
METR ran a randomized controlled trial with 16 experienced open-source developers working on 246 real issues in codebases they knew well. Half the issues allowed AI tools. Half didn't. Before the study, the developers expected AI to speed them up by 24%. When it was over, they took 19% longer on the AI-assisted issues, and they still walked away believing AI had made them 20% faster.
Read this gap again. Objectively slower. Subjectively certain they'd sped up. Nobody in this study was lying to anyone. They were experiencing exactly what happens when a tool feels helpful in the moment and the bill only shows up later.
Stack Overflow's 2025 Developer Survey found the same pattern from a different angle. Trust in AI accuracy has dropped to 29%, down from 40% the year before, while 80% of developers keep using the tools anyway. The top complaint, from 45% of respondents, is AI output described as "almost right, but not quite," and 66% say they spend extra time correcting it.
Sit with this for a second. The people closest to the tool, the ones who read every line it produces, don't trust it and use it constantly at the same time. They know exactly how wrong it gets and still struggle to reliably tell you whether it's helping. If experienced developers checking code line by line wrestle with this, what chance does a leader have, reading a paragraph of AI-generated reasoning about a decision with no way to verify the parts mattering most: the politics, the history, the people?

Why Leaders Hand Over the Call Anyway
Three reasons, and none of them have anything to do with whether the technology is good or bad.
Speed pressure. A decision needs making now, and AI answers in seconds. Speed feels like competence. It isn't the same thing, and treating it as a substitute is where trouble starts.
Cover. If the call goes wrong, "the AI recommended it" is an easier sentence to say in a postmortem than "I decided, and I was wrong." Leaders reach for this kind of cover more often than they'd admit, and rarely notice they're doing it in the moment.
Confidence theater. Quoting a model sounds objective. "My gut says we ship" sounds like a guess. "I ran the analysis and this is what came back" sounds like rigor, even when the analysis is a paragraph from a chatbot with zero visibility into your team, your customers, or your history with this exact bug.
None of those three reasons say anything about whether the AI's answer was right. This should worry you more than the accuracy numbers do, because it means the decision to defer happens before anyone checks the output at all.
I saw this dynamic firsthand years before AI tools existed in their current form, watching managers lean on whatever authority was closest at hand, a policy document, a consultant's slide deck, a spreadsheet nobody fully understood, instead of standing behind their own read of the room. AI didn't invent this pattern. It made it faster and easier to hide inside.
What AI Is Genuinely Good At
I use AI tools every week, and I'm not arguing you should stop. I'm arguing you should know exactly what job you're handing it.
AI excels at drafting options fast, surfacing data you'd have missed, running a scenario six different ways before your coffee goes cold, and spotting patterns across more information than a human head would hold at once. Use it for all of this. It's a research assistant with an unlimited attention span and zero context about your organization's politics.
This last part is the whole point.
The Job AI Cannot Do
A model doesn't sit in the room when the decision lands badly. It doesn't know your ops lead is already stretched thin, or the customer you're about to disappoint recently renewed a three-year contract, or your team stopped trusting the last "data-driven" call you made and is watching to see whether this one is any different.
Owning a decision means standing in front of people when it goes wrong and saying "I made this call, here's why, here's what I got wrong." AI cannot do this part. It cannot be accountable, because accountability requires something to lose. A model has nothing at stake. You do.
I wrote about empowering people rather than dictating to them on Step It Up HR, and the same principle applies here in reverse. Empowerment means the human closest to the consequence keeps the authority. Outsourcing your judgment to a model is the opposite move, dressed up as modern practice.

A Simple Rule I Use
Three steps, and I don't skip any of them, no matter how tight the deadline feels.
Write your own answer first. Before opening any AI tool, decide what you'd do based on what you already know. This takes two minutes and it's the step everyone skips, because it feels slower in a moment when slower feels like the enemy.
Then ask for a range of options, not one answer. Prompt for three approaches with tradeoffs, not a single recommendation. A single answer invites you to defer to it without noticing. A range forces you to keep choosing, which is the whole job.
Compare, then put your name on it. Where your instinct and the AI's output disagree, dig into why. This is where the real thinking happens. Then say the decision out loud, in the room, as yours. Not "the analysis suggested." Yours.
This isn't slower in any meaningful way. Writing your own answer first takes minutes. Skipping it costs you the one thing making you a leader instead of an expensive relay station between a chatbot and your team.
Where This Bites Hardest
Watch for the moment a team starts prefacing pushback with "well, if the AI says so." I've heard it in planning meetings, in performance reviews, even in decisions about who gets let go. Each time, it signals the same thing: the room has quietly agreed a tool with no stake in the outcome gets the final word, and everyone with actual stakes has gone silent.
If you notice this happening on your team, name it directly. Ask "what would we have decided without this tool?" out loud, in the meeting, and wait for a real answer. If nobody has one, you've found the problem, and it isn't the AI.
The Question Worth Sitting With
Next time you catch yourself about to repeat an AI's answer to your team as though it settles the matter, stop and ask what you'd have said before opening the tool. If you don't know, this isn't a technology problem. It's a leadership problem wearing a technology costume.
The tool informs the call. It doesn't make it. The moment you let it, you've stopped leading and started narrating.