
In early 2024, a major AI model release was something you'd notice. You'd block off an afternoon, test it against your prompts, decide whether to switch, and move on. It happened roughly twice a year.
In Q1 2026, there were 255 model releases. One significant new model every 72 hours. In April alone, GPT-5.5, DeepSeek V4 Pro, Grok 4.3, Gemini's Gemma 4, and Llama 4 Maverick all landed within weeks of each other. The model topping the benchmark charts when you started building your product is two generations old by the time you ship it.
I've been building StepUp2BAT on top of AI for the past year. I've made nearly every mistake possible when it comes to coupling product decisions to specific model behaviour. Here's what I've learned.
The Real Problem Isn't the Model Updates
The model updates themselves are fine. Better models mean better outputs, lower costs, more capability for your users.
The problem is what happens to your product when the model underneath it changes.
Your product isn't "a call to an API." It's a set of prompts tuned to how a specific model formats its responses. It's UI designed around the length and structure of outputs you tested last month. It's customer training built around the way the model phrases things. Change the model, and all of those shift underneath your customers' feet.
Your customers, meanwhile, are still figuring out the last update.
The Trap Most Product Teams Fall Into
Most teams do one of two things.
They freeze. They pin to a specific model version and ship. Then they ignore every release until something forces a migration... a pricing change, a deprecation notice, a competitor shipping on a clearly better model. When the forced migration comes, it's expensive and messy.
They chase. They upgrade eagerly with each major release. Prompts get rewritten quarterly. Evals shift. UI copy gets revisited. Engineers spend 30% of their sprints on migration work rather than shipping new features. The product is always in motion but never improving for users.
Neither approach works.
Build for Behaviours, Not Models
When designing a feature in StepUp2BAT, I don't write "call Claude Sonnet 4.6 and get this output." I write "get a structured assessment of manager behaviour from the survey response." The specific model is a detail my application shouldn't need to know.
This is the abstraction layer approach. It changes everything about how you think about product architecture.
How the Abstraction Layer Works
Think of it as a thin interface between your application code and the AI provider. Your application code asks for a "sentiment analysis" or a "behaviour pattern summary"... not for a specific model to run a specific prompt. The adapter layer handles model selection, prompt formatting, and output parsing.
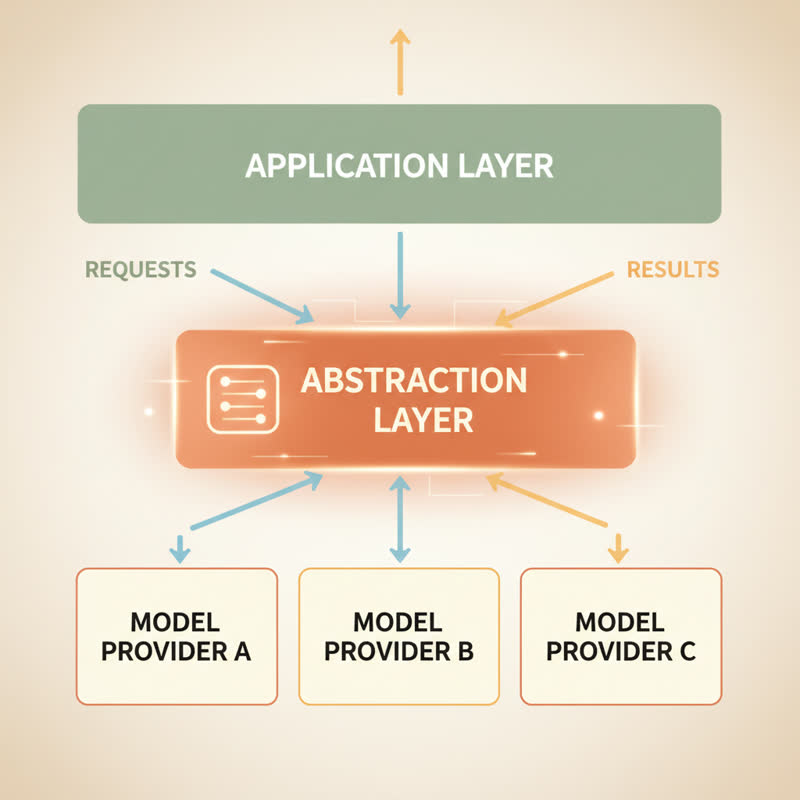
A guide for startup CTOs on avoiding LLM lock-in identifies four pressure points worth knowing:
- Interface and SDK lock-in. When your business logic references provider-specific types throughout your codebase, swapping models means touching dozens of files.
- Prompt lock-in. Over-tuning prompts to one model's quirks means you're not writing prompts. You're writing workarounds.
- Data lock-in. Uploading proprietary data into vendor-managed fine-tuning makes extraction painful later.
- Workflow lock-in. Embedding business logic in vendor-specific orchestration tools creates dependencies you don't own.
Fixing these isn't pessimism about any particular provider. It's keeping your options open while the race continues around you.
Three Concrete Changes Worth Making
Design prompts for structured outputs, not for model style.
I ask the model to return JSON with a schema I define and validate. Not "the model usually formats the list like this." When you rely on implicit formatting, model updates break your parsing. When you demand explicit structure, the model change becomes invisible to your application code.
Keep all model-specific configuration in one place.
Model version, temperature settings, any provider-specific parameters... these live in a single config file. Not scattered across the codebase. When we want to test a new model, we change one file and run our evals.
Run evals on a schedule, not only on release day.
Every week, our evaluation suite runs against the outputs we care about. Not benchmarks... our outputs, with our prompts, measuring what our customers care about. When a model update changes behaviour, we catch it before a customer does.
This last one matters more than people think. The evaluation burden of 72-hour model releases now exceeds most organisations' capacity to systematically test new models. If you don't have a scheduled eval process, you're flying blind.
Your Moat Isn't the Model

At 255 model releases in one quarter, no individual model has permanent dominance. The kersai.com March 2026 analysis notes models rated best-in-class in January are regularly outperformed by April.
If "we use [specific model]" is your product's moat, you don't have one. Any competitor with the same API key has the same moat.
The real defensibility in AI products sits above the model layer. Domain expertise shaping what you ask the model and how you interpret the answers. Proprietary data your product accumulates over time. Customer trust in your interpretation of outputs. Workflow integrations making switching costly.
When I think about what makes StepUp2BAT defensible, it isn't which model runs under the hood. It's the expertise we've developed around what good manager behaviour looks like, how to ask about it in survey form, and how to translate AI analysis into feedback managers act on. None of it disappears when the next model drops.
The Question Worth Asking Today
If your primary AI provider announced a 6-month deprecation of your current model version tomorrow, how painful would the migration be?
If the answer makes you wince, you have architecture work to do. Not because anything is about to break, but because at 72 hours per release cycle, something will eventually force you to move. Better to be ready than reactive.
April 2026's wave of releases brought autonomous OS control, trillion-parameter open-weight models, and real-time data integration. New capabilities arrive monthly. Prices keep falling.
But your product's job isn't to celebrate each new model. It's to deliver consistent value to your users week after week, regardless of what's happening beneath the surface.
Build on bedrock. Let the models do their race.
What does your AI architecture look like? Are you pinned to a specific model version, or building model-agnostic? I'm curious what's working for other builders.