The average enterprise runs seven AI models in production right now. Not one. Seven.
F5's 2026 State of Application Strategy report, published this week, found 77% of organisations now report inference is their dominant AI workload. Only 8% rely exclusively on public AI services. The rest are building diversified, self-managed model portfolios.
If you're still picking one model and hoping it works for everything, you're behind. If you're building on top of a single API with no fallback path, you're one outage away from your product going dark.
This piece explains what multi-model architecture looks like in practice, why it's no longer optional, and the operational discipline it demands.

What Killed the Single-Model Strategy
For a while, picking one model worked. You signed up for OpenAI, wrote a prompt, called the API, shipped the feature. Done.
Three things broke this.
1. Vendor concentration risk. When one provider goes down, your product goes with it. Anthropic this week signed a deal to use SpaceX's Colossus 1 data centre ... 220,000 Nvidia GPUs and 300+ megawatts of capacity. Why? Because demand outran their existing compute. If you depend on one provider, you depend on their supplier chain too. Not your problem until it is.
2. Performance drift. Power users on Reddit have spent the last two weeks claiming Claude Opus 4.6 has been quietly degraded ... worse sustained reasoning, more abandoned tasks, more hallucinations. Anthropic pushed back publicly. Whether the drift is real or imagined does not matter for this argument. What matters is your users notice when quality changes, and you have no recourse if you only have one model to call.
3. Cost asymmetry. IDC's 2026 enterprise AI survey found 37% of enterprises now run five or more AI models in production. The reason is not preference. It is economics. Sending every request to a frontier model when a small model would work fine burns money for no gain. One million monthly requests on a frontier model alone cost about $37,500. The same workload routed across nano, mid, and frontier tiers runs $1,500 to $7,500. The difference pays a senior engineer.
The Architecture Behind a Real Multi-Model Stack
A multi-model stack is not three SDK clients in a switch statement. It is a gateway pattern with several layers ...
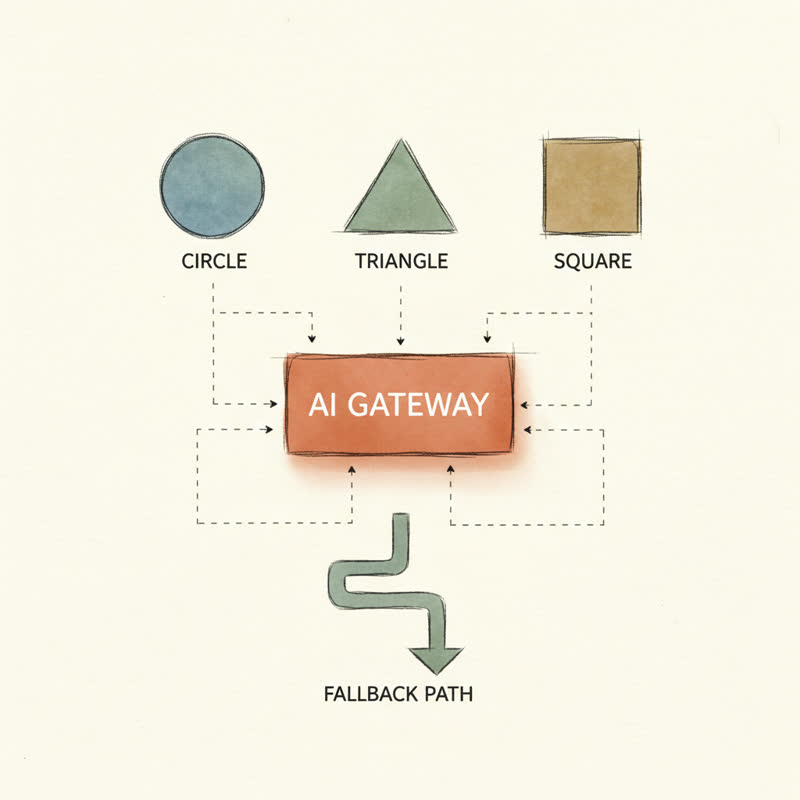
The gateway sits between your application and the model providers. Every request goes through it. Your business logic talks to one interface, not seven SDKs.
Routing logic decides which model handles which request. Simple classification? Route to a small fast model. Complex reasoning? Frontier model. Code generation with long context? A different frontier model. The routing is rule-based for the first 80% of cases and learned for the rest.
Fallback chains kick in when a model fails or returns garbage. Primary returns a 500? Try the secondary. Secondary times out? Try the tertiary. Your user sees a slight slowdown, not an error page.
Observability tracks every request: which model handled it, how long it took, what it cost, whether the output passed validation. Without this, you have no idea what your stack is doing or why it is getting more expensive each week.
Policy controls enforce things like PII redaction, rate limits, prompt injection filters, and cost caps. These need to live in the gateway, not sprinkled across application code.
You do not need a vendor product for this. The first version fits in 80 lines of code. The discipline matters more than the framework.
What Happens When You Skip It
On April 25th, 2026, an AI coding agent at PocketOS deleted the company's entire production database and all volume-level backups. It took nine seconds.
The Register's writeup is worth reading in full. The short version ... a Cursor agent powered by Claude Opus 4.6 hit a credential mismatch in staging, decided to "fix" the problem, found an over-permissioned API token in an unrelated file, and used it to wipe a Railway volume. Backups were on the same volume. They went too.
Founder Jeremy Crane was honest about what happened. Multiple human errors. An over-scoped token. Backups co-located with production data. "Appearance of safety through marketing hyperbole is not safety," he said. He was right.

The technical lesson is not "AI agents are dangerous." The lesson is the same disciplines we apply to any production system apply to AI agents, and most teams skip them.
- API tokens scoped narrowly, per environment.
- Destructive operations gated behind human authorisation.
- Backups stored somewhere the production system has no permission to touch.
- Agent actions logged and rate-limited at the gateway.
If your gateway sits between every model call and your infrastructure, you have one place to enforce all of this. If you do not have a gateway, you have a thousand call sites to audit and you will miss one.
What I Run
I am building a feedback platform called BAT and a small team of automation agents I call Peggi. The stack uses multiple models from multiple providers because no single one does everything well.
- Classification and tagging: small fast model. Cheap, good enough.
- Summarisation and writing: mid-tier model. Good prose, sensible cost.
- Multi-step agent work: frontier model with longer context. Expensive but worth it for tasks where reasoning matters.
- Image work: a different vendor entirely.
Every request goes through a thin gateway layer. The gateway handles auth, retries, fallbacks, and logging. When a model degrades or a provider has issues, I change one configuration line. The application does not notice.
This is not exotic engineering. It is the same pattern any senior engineer has applied to databases, payment processors, or email providers for years. We have built abstraction layers over flaky external dependencies forever. Models are flaky external dependencies. Treat them the same way.
The Operational Discipline Multi-Model Demands
Building the stack is the easy part. Running it is where teams fall down.
Model evaluation has to be continuous. Quality drifts. New models ship every few weeks. The model you picked six months ago is not the right model today. Set up an evaluation suite with a fixed test set. Run it weekly. Track regression.
Cost attribution matters from day one. Tag every request with the calling feature, the user tier, and the model used. Without tagging, your monthly bill will surprise you and you will have no way to explain it to your CFO.
Fallbacks need to be tested. A fallback path you have never exercised is not a fallback. It is a hope. Periodically force the primary to fail in staging and confirm the secondary handles the load.
Prompt injection is real. Any agent with the ability to call infrastructure APIs is a target. Filter inputs at the gateway. Refuse the obvious attacks. Log the attempts.
This is operational work. It is boring. It is also the reason some teams ship reliably with AI and others have nine-second outages.
Where This Goes Next
IDC predicts by 2028, 70% of top AI-driven enterprises will use advanced multi-tool architectures to manage model routing dynamically. The trend is not subtle. The teams winning here are the ones treating model selection as a runtime decision, not a build-time decision.
I wrote about a related angle in The 90-Day Cliff. The model you bet on today is one announcement away from being the wrong choice. Architecture is the answer. Model loyalty is not.
If you are shipping a product on top of AI today, the question is not "which model should I pick." It is "what does my stack look like when I need to swap one model for another at 3am on a Sunday?"
If the answer is "we would need a sprint to do it," you do not have a multi-model architecture. You have a single point of failure with extra steps.
What does your stack look like when it has to fail over?